| Titel | Inhalt | Suchen | Index | DOC | Handbuch der Java-Programmierung, 7. Auflage |
| << | < | > | >> | API | Kapitel 44 - Datenbankzugriffe mit JDBC |
In diesem Abschnitt wollen wir uns die zuvor eingeführten Konzepte in der Praxis ansehen. Dazu erzeugen wir eine einfache Datenbank DirDB, die Informationen zu Dateien und Verzeichnissen speichern kann. Über eine einfache Kommandozeilenschnittstelle können die Tabellen mit den Informationen aus dem lokalen Dateisystem gefüllt und auf unterschiedliche Weise abgefragt werden.
DirDB besitzt lediglich zwei Tabellen dir und file für Verzeichnisse und Dateien. Sie haben folgende Struktur:
| Name | Typ | Bedeutung |
| did | INT | Primärschlüssel |
| dname | CHAR(100) | Verzeichnisname |
| fatherdid | INT | Schlüssel Vaterverzeichnis |
| entries | INT | Anzahl der Verzeichniseinträge |
Tabelle 44.2: Die Struktur der dir-Tabelle
| Name | Typ | Bedeutung |
| fid | INT | Primärschlüssel |
| did | INT | Zugehöriges Verzeichnis |
| fname | CHAR(100) | Dateiname |
| fsize | INT | Dateigröße |
| fdate | DATE | Änderungsdatum |
| ftime | TIME | Änderungszeit |
Tabelle 44.3: Die Struktur der file-Tabelle
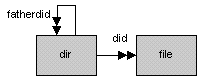
Beide Tabellen besitzen einen Primärschlüssel, der beim Anlegen eines neuen Satzes vom Programm vergeben wird. Die Struktur von dir ist baumartig; im Feld fatherid wird ein Verweis auf das Verzeichnis gehalten, in dem das aktuelle Verzeichnis enthalten ist. Dessen Wert ist im Startverzeichnis per Definition 0. Über den Fremdschlüssel did zeigt jeder Datensatz aus der file-Tabelle an, zu welchem Verzeichnis er gehört. Die Tabellen stehen demnach in einer 1:n-Beziehung zueinander. Auch die Tabelle dir steht in einer 1:n-Beziehung zu sich selbst. Abbildung 44.1 zeigt ein vereinfachtes E/R-Diagramm des Tabellendesigns.
Abbildung 44.1: E/R-Diagramm für DirDB
Das Programm DirDB.java soll folgende Anforderungen erfüllen:
Wir implementieren eine Klasse DirDB, die (der Einfachheit halber) alle Funktionen mit Hilfe statischer Methoden realisiert. Die Klasse und ihre main-Methode sehen so aus:
001 /* Listing4402.java */
002
003 import java.io.File;
004 import java.sql.*;
005 import java.text.SimpleDateFormat;
006
007 public class DirDB
008 {
009 //---Enums---------------------------------------------------
010 enum Dbms
011 {
012 JAVADB,
013 ACCESS95,
014 HSQLDB
015 }
016
017 //---Pseudo constants----------------------------------------
018 static String FILESEP = System.getProperty("file.separator");
019
020 //---Static Variables----------------------------------------
021 static Dbms db = Dbms.JAVADB;
022 static Connection con;
023 static Statement stmt;
024 static Statement stmt1;
025 static DatabaseMetaData dmd;
026 static int nextdid = 1;
027 static int nextfid = 1;
028
029 //---main-------------------------------------------------
030 public static void main(String[] args)
031 {
032 if (args.length < 1) {
033 System.out.println(
034 "usage: java DirDB [A|J|H] <command> [<options>]"
035 );
036 System.out.println("");
037 System.out.println("command options");
038 System.out.println("---------------------------------");
039 System.out.println("POPULATE <directory>");
040 System.out.println("COUNT");
041 System.out.println("FINDFILE <name>");
042 System.out.println("FINDDIR <name>");
043 System.out.println("BIGGESTFILES <howmany>");
044 System.out.println("CLUSTERING <clustersize>");
045 System.exit(1);
046 }
047 if (args[0].equalsIgnoreCase("A")) {
048 db = Dbms.ACCESS95;
049 } else if (args[0].equalsIgnoreCase("H")) {
050 db = Dbms.HSQLDB;
051 }
052 try {
053 if (args[1].equalsIgnoreCase("populate")) {
054 open();
055 createTables();
056 populate(args[2]);
057 close();
058 } else if (args[1].equalsIgnoreCase("count")) {
059 open();
060 countRecords();
061 close();
062 } else if (args[1].equalsIgnoreCase("findfile")) {
063 open();
064 findFile(args[2]);
065 close();
066 } else if (args[1].equalsIgnoreCase("finddir")) {
067 open();
068 findDir(args[2]);
069 close();
070 } else if (args[1].equalsIgnoreCase("biggestfiles")) {
071 open();
072 biggestFiles(Integer.parseInt(args[2]));
073 close();
074 } else if (args[1].equalsIgnoreCase("clustering")) {
075 open();
076 clustering(Integer.parseInt(args[2]));
077 close();
078 }
079 } catch (SQLException e) {
080 while (e != null) {
081 System.err.println(e.toString());
082 System.err.println("SQL-State: " + e.getSQLState());
083 System.err.println("ErrorCode: " + e.getErrorCode());
084 e = e.getNextException();
085 }
086 System.exit(1);
087 } catch (Exception e) {
088 System.err.println(e.toString());
089 System.exit(1);
090 }
091 }
092 }
|
In main
wird zunächst ein usage-Text definiert, der immer dann
ausgegeben wird, wenn das Programm ohne Argumente gestartet wird.
Die korrekte Aufrufsyntax ist:
java DirDB [A|J|H] <command> [<options>]
Nach dem Programmnamen folgt zunächst der Buchstabe »A«, »J« oder »H«, um anzugeben, ob die Access-, Java DB- oder HSQLDB-Datenbank verwendet werden soll. Das nächste Argument gibt den Namen des gewünschten Kommandos an. In der folgenden verschachtelten Verzweigung werden gegebenenfalls weitere Argumente gelesen und die Methode zum Ausführen des Programms aufgerufen. Den Abschluss der main-Methode bildet die Fehlerbehandlung, bei der die Ausnahmen des Typs SQLException und Exception getrennt behandelt werden.
 |
Das vollständige Programm findet sich auf der DVD zum Buch unter dem Namen DirDB.java. In diesem Abschnitt sind zwar auch alle Teile abgedruckt, sie finden sich jedoch nicht zusammenhängend wieder, sondern sind über die verschiedenen Unterabschnitte verteilt. |
|
|
Wie in Listing 44.2 zu sehen ist, rufen alle Kommandos zunächst die Methode open zum Öffnen der Datenbank auf. Anschließend führen sie ihre spezifischen Kommandos aus und rufen dann close auf, um die Datenbank wieder zu schließen.
Beim Öffnen der Datenbank wird zunächst mit Class.forName der passende Datenbanktreiber geladen und beim Treibermanager registriert. Anschließend besorgt das Programm ein Connection-Objekt, das an die statische Variable con gebunden wird. An dieser Stelle sind die potenziellen Code-Unterschiede zwischen den beiden Datenbanken gut zu erkennen:
001 /**
002 * Öffnet die Datenbank.
003 */
004 public static void open()
005 throws Exception
006 {
007 //Treiber laden und Connection erzeugen
008 if (db == Dbms.JAVADB) {
009 Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
010 con = DriverManager.getConnection(
011 "jdbc:derby:dirdb;create=true");
012 } else if (db == Dbms.HSQLDB) {
013 Class.forName("org.hsqldb.jdbcDriver");
014 con = DriverManager.getConnection(
015 "jdbc:hsqldb:hsqldbtest",
016 "SA",
017 ""
018 );
019 } else {
020 Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
021 con = DriverManager.getConnection("jdbc:odbc:DirDB");
022 }
023 //Metadaten ausgeben
024 dmd = con.getMetaData();
025 System.out.println("");
026 System.out.println("Connection URL: " + dmd.getURL());
027 System.out.println("Driver Name: " + dmd.getDriverName());
028 System.out.println("Driver Version: " + dmd.getDriverVersion());
029 System.out.println("");
030 //Statementobjekte erzeugen
031 stmt = con.createStatement();
032 stmt1 = con.createStatement();
033 }
034
035 /**
036 * Schließt die Datenbank.
037 */
038 public static void close()
039 throws SQLException
040 {
041 stmt.close();
042 stmt1.close();
043 con.close();
044 }
|
Nachdem die Verbindung hergestellt wurde, liefert der Aufruf von getMetaData ein Objekt des Typs DatabaseMetaData. Es kann dazu verwendet werden, weitere Informationen über die Datenbank abzufragen. Wir geben lediglich den Connection-String und Versionsinformationen zu den geladenen Treibern aus. DatabaseMetaData besitzt darüber hinaus noch viele weitere Variablen und Methoden, auf die wir hier nicht näher eingehen wollen. Am Ende von open erzeugt das Programm zwei Statement-Objekte stmt und stmt1, die in den übrigen Methoden zum Ausführen der SQL-Befehle verwendet werden. Zum Schließen der Datenbank werden zunächst die beiden Statement-Objekte und dann die Verbindung selbst geschlossen.
Um tatsächlich eine Verbindung zu einer der drei angegebenen Datenbanken herstellen zu können, müssen auf Systemebene die nötigen Voraussetzungen dafür geschaffen werden:
Unsere Anwendung geht davon aus, dass die Datenbank bereits angelegt ist, erstellt die nötigen Tabellen und Indexdateien aber selbst. Die dazu nötigen SQL-Befehle sind CREATE TABLE zum Anlegen einer Tabelle und CREATE INDEX zum Anlegen einer Indexdatei. Diese Befehle werden mit der Methode executeUpdate des Statement-Objekts ausgeführt, denn sie produzieren keine Ergebnismenge, sondern als DDL-Anweisungen lediglich den Rückgabewert 0. Das Anlegen der Tabellen erfolgt mit der Methode createTables:
001 /**
002 * Legt die Tabellen an.
003 */
004 public static void createTables()
005 throws SQLException
006 {
007 //Anlegen der Tabelle dir
008 try {
009 stmt.executeUpdate("DROP TABLE dir");
010 } catch (SQLException e) {
011 //Nichts zu tun
012 }
013 stmt.executeUpdate("CREATE TABLE dir (" +
014 "did INT," +
015 "dname CHAR(100)," +
016 "fatherdid INT," +
017 "entries INT)"
018 );
019 stmt.executeUpdate("CREATE INDEX idir1 ON dir ( did )");
020 stmt.executeUpdate("CREATE INDEX idir2 ON dir ( fatherdid )");
021 //Anlegen der Tabelle file
022 try {
023 stmt.executeUpdate("DROP TABLE file");
024 } catch (SQLException e) {
025 //Nichts zu tun
026 }
027 stmt.executeUpdate("CREATE TABLE file (" +
028 "fid INT ," +
029 "did INT," +
030 "fname CHAR(100)," +
031 "fsize INT," +
032 "fdate DATE," +
033 "ftime CHAR(5))"
034 );
035 stmt.executeUpdate("CREATE INDEX ifile1 ON file ( fid )");
036 }
|
|
Um die Tabellen zu löschen, falls sie bereits vorhanden sind, wird zunächst die Anweisung DROP TABLE ausgeführt. Sie ist in einem eigenen try-catch-Block gekapselt, denn manche Datenbanken lösen eine Ausnahme aus, falls die zu löschenden Tabellen nicht existieren. Diesen »Fehler« wollen wir natürlich ignorieren und nicht an den Aufrufer weitergeben. |
|
|
Nachdem die Tabellen angelegt wurden, können sie mit der Methode populate gefüllt werden. populate bekommt dazu vom Rahmenprogramm den Namen des Startverzeichnisses übergeben, das rekursiv durchlaufen werden soll, und ruft addDirectory auf, um das erste Verzeichnis mit Hilfe des Kommandos INSERT INTO (das ebenfalls an executeUpdate übergeben wird) in die Tabelle dir einzutragen. Der Code sieht etwas unleserlich aus, weil einige Stringliterale einschließlich der zugehörigen einfachen Anführungsstriche übergeben werden müssen. Sie dienen in SQL-Befehlen als Begrenzungszeichen von Zeichenketten.
Für das aktuelle Verzeichnis wird dann ein File-Objekt erzeugt und mit listFiles eine Liste der Dateien und Verzeichnisse in diesem Verzeichnis erstellt. Jede Datei wird mit einem weiteren INSERT INTO in die file-Tabelle eingetragen, für jedes Unterverzeichnis ruft addDirectory sich selbst rekursiv auf.
|
Am Ende wird mit einem UPDATE-Kommando die Anzahl der Einträge im aktuellen Verzeichnis in das Feld entries der Tabelle dir eingetragen. Der Grund für diese etwas umständliche Vorgehensweise (wir hätten das auch gleich beim Anlegen des dir-Satzes erledigen können) liegt darin, dass wir auch ein Beispiel für die Anwendung der UPDATE-Anweisung geben wollten. |
|
|
001 /**
002 * Durchläuft den Verzeichnisbaum rekursiv und schreibt
003 * Verzeichnis- und Dateinamen in die Datenbank.
004 */
005 public static void populate(String dir)
006 throws Exception
007 {
008 addDirectory(0, "", dir);
009 }
010
011 /**
012 * Fügt das angegebene Verzeichnis und alle
013 * Unterverzeichnisse mit allen darin enthaltenen
014 * Dateien zur Datenbank hinzu.
015 */
016 public static void addDirectory(
017 int fatherdid, String parent, String name
018 )
019 throws Exception
020 {
021 String dirname = "";
022 if (parent.length() > 0) {
023 dirname = parent;
024 if (!parent.endsWith(FILESEP)) {
025 dirname += FILESEP;
026 }
027 }
028 dirname += name;
029 System.out.println("processing " + dirname);
030 File dir = new File(dirname);
031 if (!dir.isDirectory()) {
032 throw new Exception("not a directory: " + dirname);
033 }
034 //Verzeichnis anlegen
035 int did = nextdid++;
036 stmt.executeUpdate(
037 "INSERT INTO dir VALUES (" +
038 did + "," +
039 "\'" + name + "\'," +
040 fatherdid + "," +
041 "0)"
042 );
043 //Verzeichniseinträge lesen
044 File[] entries = dir.listFiles();
045 //Verzeichnis durchlaufen
046 for (int i = 0; i < entries.length; ++i) {
047 if (entries[i].isDirectory()) {
048 addDirectory(did, dirname, entries[i].getName());
049 } else {
050 java.util.Date d = new java.util.Date(
051 entries[i].lastModified()
052 );
053 SimpleDateFormat sdf;
054 //Datum
055 sdf = new SimpleDateFormat("yyyy-MM-dd");
056 String date = sdf.format(d);
057 //Zeit
058 sdf = new SimpleDateFormat("HH:mm");
059 String time = sdf.format(d);
060 //Satz anhängen
061 stmt.executeUpdate(
062 "INSERT INTO file VALUES (" +
063 (nextfid++) + "," +
064 did + "," +
065 "\'" + entries[i].getName() + "\'," +
066 entries[i].length() + "," +
067 "{d \'" + date + "\'}," +
068 "\'" + time + "\')"
069 );
070 System.out.println(" " + entries[i].getName());
071 }
072 }
073 //Anzahl der Einträge aktualisieren
074 stmt.executeUpdate(
075 "UPDATE dir SET entries = " + entries.length +
076 " WHERE did = " + did
077 );
078 }
|
|
Hier tauchen die beiden im Rahmenprogramm definierten statischen Variablen nextdid und nextfid wieder auf. Sie liefern die Primärschlüssel für Datei- und Verzeichnissätze und werden nach jedem eingefügten Satz automatisch um eins erhöht. Dass dieses Verfahren nicht mehrbenutzerfähig ist, leuchtet ein, denn die Zähler werden lokal zur laufenden Applikation erhöht. Eine bessere Lösung bieten Primärschlüsselfelder (sogenannte Autoincrement-Felder), die beim Einfügen von der Datenbank einen automatisch hochgezählten eindeutigen Wert erhalten. Meist kann ein solches Feld in der INSERT INTO-Anweisung einfach ausgelassen werden. Alternativ könnten Schlüsselwerte vor dem Einfügen aus einer zentralen Key-Tabelle geholt und transaktionssicher hochgezählt werden. |
|
|
Das COUNT-Kommando soll die Anzahl der Verzeichnisse und Dateien zählen, die mit dem POPULATE-Kommando in die Datei eingefügt wurden. Wir verwenden dazu ein einfaches SELECT-Kommando, das mit der COUNT(*)-Option die Anzahl der Sätze in einer Tabelle zählt:
001 /**
002 * Gibt die Anzahl der Dateien und Verzeichnisse aus.
003 */
004 public static void countRecords()
005 throws SQLException
006 {
007 ResultSet rs = stmt.executeQuery(
008 "SELECT count(*) FROM dir"
009 );
010 if (!rs.next()) {
011 throw new SQLException("SELECT COUNT(*): no result");
012 }
013 System.out.println("Directories: " + rs.getInt(1));
014 rs = stmt.executeQuery("SELECT count(*) FROM file");
015 if (!rs.next()) {
016 throw new SQLException("SELECT COUNT(*): no result");
017 }
018 System.out.println("Files: " + rs.getInt(1));
019 rs.close();
020 }
|
Die SELECT-Befehle werden mit der Methode executeQuery an das Statement-Objekt übergeben, denn wir erwarten nicht nur eine einfache Ganzzahl als Rückgabewert, sondern eine komplette Ergebnismenge. Die Besonderheit liegt in diesem Fall darin, dass wegen der Spaltenangabe COUNT(*) lediglich ein einziger Satz zurückgegeben wird, der auch nur ein einziges Feld enthält. Auf dieses können wir am einfachsten über seinen numerischen Index 1 zugreifen und es durch Aufruf von getInt gleich in ein int umwandeln lassen. Das Ergebnis geben wir auf dem Bildschirm aus und wiederholen anschließend dieselbe Prozedur für die Tabelle file.
Um eine bestimmte Datei oder Tabelle in unserer Datenbank zu suchen, verwenden wir ebenfalls ein SELECT-Statement. Im Gegensatz zu vorher lassen wir uns nun mit der Spaltenangabe »*« alle Felder der Tabelle geben. Zudem hängen wir an die Abfrageanweisung eine WHERE-Klausel an, um eine Suchbedingung formulieren zu können. Mit Hilfe des LIKE-Operators führen wir eine Mustersuche durch, bei der die beiden SQL-Wildcards »%« (eine beliebige Anzahl Zeichen) und »_« (ein einzelnes beliebiges Zeichen) verwendet werden können.
Die von executeQuery zurückgegebene Ergebnismenge wird mit next Satz für Satz durchlaufen und auf dem Bildschirm ausgegeben. Mit Hilfe der Methode getDirPath wird zuvor der zugehörige Verzeichnisname rekonstruiert und vor dem Dateinamen ausgegeben. Dazu wird in einer Schleife zur angegebenen did (Verzeichnisschlüssel) so lange das zugehörige Verzeichnis gesucht, bis dessen fatherdid 0 ist, also das Startverzeichnis erreicht ist. Rückwärts zusammengebaut und mit Trennzeichen versehen, ergibt diese Namenskette den kompletten Verzeichnisnamen.
|
|
Der in dieser Methode verwendete ResultSet wurde mit dem zweiten Statement-Objekt stmt1 erzeugt. Hätten wir dafür die zu diesem Zeitpunkt noch geöffnete Variable stmt verwendet, wäre das Verhalten des Programms undefiniert gewesen, weil die bestehende Ergebnismenge durch das Erzeugen einer neuen Ergebnismenge auf demselben Statement-Objekt ungültig geworden wäre. |
|
|
001 /**
002 * Gibt eine Liste aller Files auf dem Bildschirm aus,
003 * die zu dem angegebenen Dateinamen passen. Darin dürfen
004 * die üblichen SQL-Wildcards % und _ enthalten sein.
005 */
006 public static void findFile(String name)
007 throws SQLException
008 {
009 String query = "SELECT * FROM file " +
010 "WHERE fname LIKE \'" + name + "\'";
011 ResultSet rs = stmt.executeQuery(query);
012 while (rs.next()) {
013 String path = getDirPath(rs.getInt("did"));
014 System.out.println(
015 path + FILESEP +
016 rs.getString("fname").trim()
017 );
018 }
019 rs.close();
020 }
021
022 /**
023 * Liefert den Pfadnamen zu dem Verzeichnis mit dem
024 * angegebenen Schlüssel.
025 */
026 public static String getDirPath(int did)
027 throws SQLException
028 {
029 String ret = "";
030 while (true) {
031 ResultSet rs = stmt1.executeQuery(
032 "SELECT * FROM dir WHERE did = " + did
033 );
034 if (!rs.next()) {
035 throw new SQLException(
036 "no dir record found with did = " + did
037 );
038 }
039 ret = rs.getString("dname").trim() +
040 (ret.length() > 0 ? FILESEP + ret : "");
041 if ((did = rs.getInt("fatherdid")) == 0) {
042 break;
043 }
044 }
045 return ret;
046 }
|
Das DirDB-Programm bietet mit dem Kommando FINDDIR auch die Möglichkeit, nach Verzeichnisnamen zu suchen. Die Implementierung dieser Funktion ähnelt der vorigen und wird durch die Methode findDir realisiert:
001 /**
002 * Gibt eine Liste aller Verzeichnisse auf dem Bildschirm
003 * aus, die zu dem angegebenen Verzeichnisnamen passen.
004 * Darin dürfen die üblichen SQL-Wildcards % und _
005 * enthalten sein.
006 */
007 public static void findDir(String name)
008 throws SQLException
009 {
010 String query = "SELECT * FROM dir " +
011 "WHERE dname LIKE \'" + name + "\'";
012 ResultSet rs = stmt.executeQuery(query);
013 while (rs.next()) {
014 System.out.println(
015 getDirPath(rs.getInt("did")) +
016 " (" + rs.getInt("entries") + " entries)"
017 );
018 }
019 rs.close();
020 }
|
|
Wird das DirDB-Programm von der Kommandozeile aufgerufen, kann es
unter Umständen schwierig sein, die Wildcards »%« oder
»_« einzugeben, weil sie vom Betriebssystem oder der Shell
als Sonderzeichen angesehen werden. Durch Voranstellen des passenden
Escape-Zeichens (das könnte beispielsweise der Backslash sein)
kann die Sonderbedeutung aufgehoben werden. In der DOS-Box von Windows
kann die Sonderbedeutung des »%« nur aufgehoben werden,
indem das Zeichen »%« doppelt geschrieben wird. Soll beispielsweise
nach allen Dateien mit der Erweiterung .java
gesucht werden, so ist DirDb
unter Windows wie folgt aufzurufen:
Weiterhin ist zu beachten, dass die Interpretation der Wildcards von
den unterschiedlichen Datenbanken leider nicht einheitlich gehandhabt
wird. Bei der Access-Datenbank ist die Ergebnismenge des obigen Statements
leer. Der Grund kann - je nach verwendeter Version - darin liegen,
dass entweder der Stern »*« anstelle des »%« als
Wildcard erwartet wird oder dass die Leerzeichen am Ende des Felds
als signifikant angesehen werden und daher auch hinter dem
Suchbegriff ein Wildcard-Zeichen angegeben werden muss:
|
|
|
Eine ähnliche SELECT-Anweisung begegnet uns, wenn wir uns die Aufgabe stellen, die howmany größten Dateien unserer Datenbank anzuzeigen. Hierzu fügen wir eine ORDER BY-Klausel an und sortieren die Abfrage absteigend nach der Spalte fsize. Von der Ergebnismenge geben wir dann die ersten howmany Elemente aus:
001 /**
002 * Gibt die howmany größten Dateien aus.
003 */
004 public static void biggestFiles(int howmany)
005 throws SQLException
006 {
007 ResultSet rs = stmt.executeQuery(
008 "SELECT * FROM file ORDER BY fsize DESC"
009 );
010 for (int i = 0; i < howmany; ++i) {
011 if (rs.next()) {
012 System.out.print(
013 getDirPath(rs.getInt("did")) +
014 FILESEP + rs.getString("fname").trim()
015 );
016 System.out.format("%10d\n", rs.getInt("fsize"));
017 }
018 }
019 rs.close();
020 }
|
Bevor wir uns weiterführenden Themen zuwenden, wollen wir uns eine letzte Anwendung unserer Beispieldatenbank ansehen. Viele Dateisysteme (allen voran das alte FAT-Dateisystem unter MS-DOS und Windows) speichern die Dateien in verketteten Zuordnungseinheiten fester Größe, den Clustern. Ist die Cluster-Größe beispielsweise 4096 Byte, so belegt eine Datei auch dann 4 kByte Speicher, wenn sie nur ein Byte groß ist. Immer, wenn die Größe einer Datei nicht ein genaues Vielfaches der Cluster-Größe ist, bleibt der letzte Cluster unvollständig belegt und wertvoller Plattenspeicher bleibt ungenutzt. Ist die Cluster-Größe hoch, wird vor allem dann viel Platz verschwendet, wenn das Dateisystem sehr viele kleine Dateien enthält. Die folgende Funktion clustering berechnet zu einer gegebenen Cluster-Größe die Summe der Dateilängen und stellt sie dem tatsächlichen Platzbedarf aufgrund der geclusterten Speicherung gegenüber:
001 /**
002 * Summiert einerseits die tatsächliche Größe aller
003 * Dateien und andererseits die Größe, die sie durch
004 * das Clustering mit der angegebenen Clustergröße
005 * belegen. Zusätzlich wird der durch das Clustering
006 * "verschwendete" Speicherplatz ausgegeben.
007 */
008 public static void clustering(int clustersize)
009 throws SQLException
010 {
011 int truesize = 0;
012 int clusteredsize = 0;
013 double wasted;
014 ResultSet rs = stmt.executeQuery(
015 "SELECT * FROM file"
016 );
017 while (rs.next()) {
018 int fsize = rs.getInt("fsize");
019 truesize += fsize;
020 if (fsize % clustersize == 0) {
021 clusteredsize += fsize;
022 } else {
023 clusteredsize += ((fsize / clustersize) + 1)*clustersize;
024 }
025 }
026 System.out.println("true size = " + truesize);
027 System.out.println("clustered size = " + clusteredsize);
028 wasted = 100 * (1 - ((double)truesize / clusteredsize));
029 System.out.println("wasted space = " + wasted + " %");
030 }
|
Um beispielsweise den Einfluss der geclusterten Darstellung bei einer
Cluster-Größe von 8192 zu ermitteln, kann das Programm
wie folgt aufgerufen werden:
java DirDB I clustering 8192
Die Ausgabe des Programms könnte dann beispielsweise so aussehen:
Connection URL: jdbc:derby:dirdb
Driver Name: Apache Derby Embedded JDBC Driver
Driver Version: 10.5.3.0 - (802917)
true size = 568519414
clustered size = 638812160
wasted space = 11.003664363558762 %
| Titel | Inhalt | Suchen | Index | DOC | Handbuch der Java-Programmierung, 7. Auflage, Addison Wesley, Version 7.0 |
| << | < | > | >> | API | © 1998, 2011 Guido Krüger & Heiko Hansen, http://www.javabuch.de |