| Titel | Inhalt | Suchen | Index | DOC | Handbuch der Java-Programmierung, 7. Auflage |
| << | < | > | >> | API | Kapitel 47 - Objektorientierte Persistenz |
Die voranstehenden Abschnitte haben gezeigt, wie man einfache Tabellen der Datenbank mit Hilfe von Java Beans abbilden und Datensätze über den EntityManager anlegen, manipulieren und löschen kann. Dabei wurde die Tabelle eins zu eins als Java-Objekt abgebildet, ohne auf die objektorientierte Struktur der verknüpften Datensätze einzugehen.
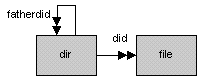
Das E/R-Diagramm unserer kleinen Datenbank aus Abschnitt 44.3 zeigt allerdings nicht nur eine, sondern zwei Tabellen, die miteinander verknüpft sind:
Abbildung 47.2: E/R-Diagramm für DirDB
Ein Verzeichnis besitzt zunächst nur eine ID did und einen Namen dname. Der in Listing 47.2 modellierte Schlüssel fatherdid verweist dagegen auf einen übergeordneten Datensatz, also ein Elternverzeichnis, und statt lediglich die Anzahl der Verzeichniseinträge entries abzubilden, wäre es schön, wenn wir gleich Zugriff auf die entsprechenden Objekte hätten. Wie dies mit der JPA realisiert werden kann, wollen wir uns im zweiten Teil dieses Kapitels ansehen.
Zunächst wollen wir uns dem Abbilden von Datenbanktabellen noch einmal von der objektorientierten Herangehensweise annähern. Dabei besteht ein Verzeichnis-Objekt zunächst einmal aus einem Namen und einer ID. Während der Name vom Anwender selbst vergeben werden muss und damit ein Pflichtattribut darstellt, handelt es sich bei der ID um einen technischen Schlüssel in der Datenbank, den der Anwender zwar auslesen, aber nicht einfach ändern kann. Das folgende Listing zeigt die Java Bean im Ausgangsstadium:
Die Klasse Verzeichnis bildet zunächst nur die beiden Attribute id in Zeile 012 und name in Zeile 013 ab. Die Namen der Attribute orientieren sich an den Java-Konventionen und wir achten darauf, dass der öffentliche Konstruktor das Pflichtfeld name übernimmt, so dass kein namenloses Verzeichnis erstellt werden kann.
Der parameterlose Konstruktor in Zeile 018 ist dem Persistenz-Framework geschuldet, das zwingend einen Standardkonstruktor benötigt. Um dessen Aufruf zu erschweren, schränken wir die Sichtbarkeit mit Hilfe des Modifiers protected ein. Da die ID des Datensatzes ausnahmslos von der Persistenzschicht verwaltet werden soll, ist in Zeile 036 auch der Zugriff auf dieses Attribut eingeschränkt.
Eine weitere Neuerung gegenüber Listing 47.2 findet sich schließlich in der Verwendung des Objekttyps Integer statt des Basistyps int für die ID des Datensatzes. Der Objekttyp hat gegenüber den Basistypen den Vorteil, dass er den Wert null annehmen und damit einen nicht definierten Zustand abbilden kann. Das ist beispielsweise dann der Fall, wenn die Instanz zwar über einen Konstruktor erzeugt, aber noch nicht in der Datenbank gespeichert wurde.
Abschließend wird die Klasse Verzeichnis um die Methoden equals und hashCode aus Abschnitt 9.1.2 erweitert, um die Identität eines Datensatzes überprüfen zu können. Diese Methoden stellen sicher, dass Hibernate einen in der Datenbank eindeutig referenzierten Datensatz über dessen ID auch javaseitig identifizieren und so beispielsweise das doppelte Laden einer logisch identischen Instanz vermeiden kann.
Als Nächstes versehen wir die Java Bean mit den für die Persistenzschicht notwendigen Metainformationen und verknüpfen sie so mit der im Hintergrund arbeitenden Datenbank. Als Alternative zu Listing 47.2 werden wir die Annotationen diesmal direkt an den Attributen, statt an den zugehörigen Getter-Methoden anbringen:
Die Annotationen @Entity, @Table, @Id und Column wurden ja bereits mit Listing 47.2 eingeführt. Neu hinzugekommen ist @GeneratedValue in Zeile 015, um der Persistenzschicht anzuzeigen, dass der Wert des Attributs automatisch erzeugt und nicht vom Benutzer gesetzt werden soll.
Analog zur Klasse Verzeichnis können wir nun auch die Klasse Datei mit dem Pflichtattribut name definieren. Dabei bilden wir der Einfachheit halber das Änderungsdatum einer Datei über ein einzelnes Attribut mit Namen date ab:
001 /* Datei.java */
002
003 import javax.persistence.*;
004 import java.util.Date;
005
006 /**
007 * Diese Klasse repräsentiert die Tabelle 'file' der 'DirDB'
008 * Jede Instanz der Klasse repräsentiert wiederum einen
009 * Datensatz
010 */
011
012 @Entity
013 @Table( name = "file" )
014 public class Datei
015 {
016 @Id
017 @GeneratedValue
018 @Column(name = "fid")
019 private Integer id;
020
021 @Column(name = "fname")
022 private String name;
023
024 @Column(name = "dsize")
025 private Integer size;
026
027 @Column(name = "fdate")
028 private Date date;
029
030 /**
031 * Geschützter Minimalkonstruktor zur Verwendung durch
032 * die Persistenzschicht
033 */
034 protected Datei() {
035 }
036
037 /**
038 * Öffentlicher Konstruktor zur Verwendung durch den Entwickler.
039 * Dieser Konstruktor definiert alle Pflichtfelder der JavaBean.
040 * @param name - Name der Datei
041 */
042 public Datei(String name)
043 {
044 this.name = name;
045 }
046
047 public Integer getId()
048 {
049 return id;
050 }
051
052 protected void setId(Integer id)
053 {
054 this.id = id;
055 }
056
057 public String getName()
058 {
059 return name;
060 }
061
062 public void setName(String name)
063 {
064 this.name = name;
065 }
066
067 public Integer getSize()
068 {
069 return size;
070 }
071
072 public void setSize(Integer size)
073 {
074 this.size = size;
075 }
076
077 public Date getDate()
078 {
079 return date;
080 }
081
082 public void setDate(Date date)
083 {
084 this.date = date;
085 }
086
087 public boolean equals(Object o)
088 {
089 if (this == o) return true;
090 if (o == null || getClass() != o.getClass()) return false;
091
092 Datei file = (File) o;
093 return !(id != null ? !id.equals(file.id) : file.id != null);
094 }
095
096 public int hashCode()
097 {
098 return id != null ? id.hashCode() : 0;
099 }
100
101 public String toString()
102 {
103 return "File[id:"+ id + ", name:" + name + "]";
104 }
105 }
|
Um auch das Datei-Objekt über den EntityManager der Persistenzschicht verwalten zu können, müssen wir die Klasse noch im Persistence Deskriptor (persistence.xml) angeben. Hierfür erweitern wir Listing 47.3 wie folgt (Zeile 015):
001 <?xml version="1.0" encoding="ISO-8859-1"?> 002 003 <!-- Persistenz Descriptor zur Konfiguration --> 004 <persistence> 005 006 <!-- Hinterlegen eines symbolischen Namens --> 007 <persistence-unit name="persistenceExample" 008 transaction-type="RESOURCE_LOCAL"> 009 010 <!-- Zu verwendende Implementierung --> 011 <provider>org.hibernate.ejb.HibernatePersistence</provider> 012 013 <!-- Persistierbare Klassen --> 014 <class>Verzeichnis</class> 015 <class>Datei</class> 016 017 <!-- Konfiguration der Hibernate Implementierung --> 018 <properties> 019 <!-- Name des intern verwendeten JDBC-Treibers --> 020 <property name="hibernate.connection.driver_class" 021 value="org.hsqldb.jdbcDriver"/> 022 023 <!-- URL der zu verwendenden Datenbank --> 024 <property name="hibernate.connection.url" 025 value="jdbc:hsqldb:hsqldbtest"/> 026 027 <!-- SQL-Dialect, den Hibernate verwenden soll --> 028 <property name="hibernate.dialect" 029 value="org.hibernate.dialect.HSQLDialect"/> 030 031 <!-- Benutzername und Passwort; Standardwerte der HSQLDB --> 032 <property name="hibernate.connection.username" value="SA"/> 033 <property name="hibernate.connection.password" value=""/> 034 035 <!-- Flag, ob Tabellen automatisch erzeugt werden sollen --> 036 <property name="hibernate.hbm2ddl.auto" value="create"/> 037 038 <!-- Flag, ob SQL-Statements ausgegeben werden sollen --> 039 <property name="hibernate.show_sql" value="true"/> 040 041 <!-- Flag, ob SQL-Statements formatiert werden sollen --> 042 <property name="hibernate.format_sql" value="true"/> 043 </properties> 044 </persistence-unit> 045 </persistence> |
persistence.xml.ext |
Das Speichern, Manipulieren und Löschen der Persistenz Beans erfolgt ganz analog zum ersten Beispiel in Listing 47.6. Der einzige Unterschied ist, dass wir die ID des Datensatzes nicht mehr selbst vorgeben, sondern von der Persistenzschicht generieren lassen.
001 /* Listing4713.java */
002
003 import javax.persistence.*;
004
005 public class Listing4713
006 {
007 public static void main(String[] args)
008 {
009 //Erzeugen einer EntityManagerFactory mit Hilfe des symbolischen
010 //Namens aus dem Persistenz Descriptor (persistence.xml)
011 EntityManagerFactory emf =
012 Persistence.createEntityManagerFactory("persistenceExample");
013
014 //Erzeugen eines EntityManagers für den Zugriff auf
015 //die Datenbank
016 EntityManager manager = emf.createEntityManager();
017
018 //Beginn einer neuen Transanktion
019 EntityTransaction tx = manager.getTransaction();
020 tx.begin();
021
022 //Erzeugen eines neuen Java-Objekts
023 Verzeichnis dir = new Verzeichnis("temp");
024
025 //Speichern des Java-Objekts mit Hilfe des EntityManagers
026 manager.persist(dir);
027
028 //Abschluss der Transaktion mit einem Commit
029 tx.commit();
030
031 // Ausgabe der Id des Datensatzes
032 System.out.println(dir.toString());
033
034 //Freigabe der Ressourcen des EntityManagers
035 manager.close();
036
037 //Schließen der EntityManagerFactory und Freigeben der
038 //belegten Ressourcen
039 emf.close();
040 }
041 }
|
Listing4713.java |
Das Verzeichnis-Objekt wird
in Zeile 023 nur
noch mit einem Namen initialisiert und erhält seine ID erst mit
dem Speichern in Zeile 026.
Die Ausgabeanweisung in Zeile 032
führt zu folgendem Ergebnis:
Directory[id:1, name:temp]
Relationale Datenbanken verknüpfen Datensätze unterschiedlicher Tabellen mit Hilfe von Fremdschlüsseln. In diesem Abschnitt wollen wir uns ansehen, wie die referentielle Integrität, also die fachliche Konsistenz der verschiedenen Fremdschlüsselbeziehungen der Datenbank, objektorientiert modelliert werden kann.
Solche Referenzen können in unterschiedlichen Kardinalitäten vorliegen:
| Kurzform | Name | Bedeutung |
| 1:1 | Eins-zu-Eins | Jeder Datensatz einer Tabelle ist höchstens einem Datensatz in der anderen Tabelle zugeordnet. |
| 1:N | Eins-zu-N | Dem Datensatz dieser Tabelle können mehrere Datensätze einer anderen Tabelle zugordnet sein. |
| N:1 | N-zu-Eins | Mehrere Datensätze dieser Tabelle können auf ein und denselben Datensatz einer anderen Tabelle verweisen. |
| M:N | M-zu-N | Der Datensatz kann von verschiedenen Datensätzen referenziert werden und gleichzeitig auf mehrere Datensätze verweisen. |
Tabelle 47.5: Kardinalitäten für Datenbankbeziehungen
In unserem Beispiel speichert jeder file-Datensatz die ID des zugehörigen dir-Datensatzes, um eindeutig anzuzeigen, zu welchem Verzeichnis die jeweilige Datei gehört. Zwischen Datei und Verzeichnis besteht also eine N:1-Beziehung, da mehrere Dateien zu genau einem Verzeichniseintrag gehören können. Aus Sicht des Verzeichnis-Objekts würde es sich umgekehrt um eine 1:N-Beziehung handeln.
Diese Referenzen lassen sich auch mit der Persistenzschicht abbilden, indem ein Objekt auf das oder die anderen Objekte verweist. Wir erweitern dazu das Verzeichnis-Objekt um eine Liste von Datei-Objekten, um die zum Verzeichnis gehörenden Dateien aufzunehmen:
Genau wie die Basisattribute einer Tabelle werden auch die referenzierten Datensätze über Annotationen mit den notwendigen Metainformationen verknüpft. Für eine 1:N-Relation genügt dabei die Angabe von @OneToMany in Zeile 024. Mit dem Attribut cascade wird das Persistenz-Framework angewiesen, bestimmte Datenbankoperationen auch auf die referenzierten Datensätze anzuwenden. Über den Parameter CascadeType.ALL in Listing 47.14 weisen wir das Framework beispielsweise an, alle Datenbankoperationen auf Verzeichnisebene auch auf die anhängenden Dateien anzuwenden.
Da die Dateiobjekte zu einem Verzeichnis jedoch nicht als unsortiertes java.util.Set, sondern als nach Namen geordnete Liste ausgelesen werden sollen, fügen wir in Zeile 025 noch eine zweite Annotation @OrderBy hinzu. Sie bewirkt, dass die Datensätze nach dem Namen der referenzierten Java Bean sortiert werden. Die Bezeichnung der Datenbankspalte, unter der der Name einer Datei abgespeichert wird, spielt hier keine Rolle, es zählt einzig der Name des Attributs in der Java Bean Datei.
Zu guter Letzt wollen wir verhindern, dass es bei einem Zugriff auf die Datei-Objekte eines Verzeichnis aufgrund einer nicht initialisierten Liste zu einer NullPointerException kommt. Deshalb erweitern wir den öffentlichen Konstruktor und initialisieren die Liste in Zeile 042. Bemerkenswert an dieser Stelle ist, dass wir den vom Persistenz-Framework verwendeten Minimalkonstruktor in Zeile 031 nicht entsprechend erweitern müssen: Auch wenn zu einem Verzeichnis keine Dateien existieren, wird das Persistenz-Framework refenzierende Collections stets leer initialisieren.
| Annotation | Beschreibung |
| @OneToMany | Modelliert eine 1:N-Relation |
| @ManyToOne | Modelliert eine N:1-Relation |
| @OneToOne | Modelliert eine 1:1-Relation |
| @ManyToMany | Modelliert eine M:N-Relation |
Tabelle 47.6: Annotationen zur Modellierung von Datenbankreferenzen
Alle Annotationen aus Tabelle 47.6 können über eine Reihe von Attributen konfiguriert werden:
| Attribut | Beschreibung |
| cascade | Welche Datenbankoperationen sollen auch auf das referenzierte Objekt angewendet werden? |
| fetch | Wann sollen die referenzierten Datensätze geladen werden? FetchType.EAGER lädt die Datensätze sofort, FetchType.LAZY lädt die Datensätze nur bei Bedarf nach. |
| mappedBy | Name des Attributs im referenzierten Datensatz, das die inverse Relation abbildet. Wird nur benötigt, wenn mehrere Rückreferenzen in Frage kommen. |
| targetEntity | Typ des referenzierten Datensatzes. Wird nur benötigt, wenn dies nicht aus der typisierten Liste hervorgeht. |
Tabelle 47.7: Attribute der Annotationen für Datenbankreferenzen
Wir können auch die inverse Relation von einer Datei auf das zugehörige Verzeichnis abbilden, also eine @ManyToOne-Beziehung:
001 /* Datei.java */
002
003 import javax.persistence.*;
004 import java.util.Date;
005
006 /**
007 * Diese Klasse repräsentiert die Tabelle 'file' der 'DirDB'
008 * Jede Instanz der Klasse repräsentiert wiederum einen
009 * Datensatz
010 */
011
012 @Entity
013 @Table( name = "file" )
014 public class Datei
015 {
016 @Id
017 @GeneratedValue
018 @Column(name = "fid")
019 private Integer id;
020
021 @Column(name = "fname")
022 private String name;
023
024 @Column(name = "dsize")
025 private Integer size;
026
027 @Column(name = "fdate")
028 private Date date;
029
030 @ManyToOne
031 @JoinColumn(name = "did")
032 private Verzeichnis directory;
033
034 /**
035 * Geschützter Minimalkonstruktor zur Verwendung von Hibernate
036 */
037 protected Datei() {
038 }
039
040 /**
041 * Öffentlicher Konstruktor zur Verwendung durch den Entwickler.
042 * Dieser Konstruktor definiert alle Pflichtfelder der JavaBean.
043 * @param name - Name der Datei
044 */
045 public Datei(String name)
046 {
047 this.name = name;
048 }
049
050 public Integer getId()
051 {
052 return id;
053 }
054
055 protected void setId(Integer id)
056 {
057 this.id = id;
058 }
059
060 public String getName()
061 {
062 return name;
063 }
064
065 public void setName(String name)
066 {
067 this.name = name;
068 }
069
070 public Integer getSize()
071 {
072 return size;
073 }
074
075 public void setSize(Integer size)
076 {
077 this.size = size;
078 }
079
080 public Date getDate()
081 {
082 return date;
083 }
084
085 public void setDate(Date date)
086 {
087 this.date = date;
088 }
089
090 public Verzeichnis getDirectory()
091 {
092 return directory;
093 }
094
095 public void setDirectory(Verzeichnis directory)
096 {
097 this.directory = directory;
098 }
099
100 public boolean equals(Object o)
101 {
102 if (this == o) return true;
103 if (o == null || getClass() != o.getClass()) return false;
104
105 Datei file = (Datei) o;
106 return !(id != null ? !id.equals(file.id) : file.id != null);
107 }
108
109 public int hashCode()
110 {
111 return id != null ? id.hashCode() : 0;
112 }
113
114 public String toString()
115 {
116 return "File[id:"+ id + ", name:" + name + "]";
117 }
118 }
|
Datei.java |
Nun sind die beiden Persistenz Beans Verzeichnis und Datei miteinander verknüpft und referenzieren sich in beide Richtungen. Aus Sicht der Java-Objekte können wir jetzt auf einfache Weise die Dateien eines Verzeichnisses ausgeben oder das Elternverzeichnis einer Datei ermitteln. Dank der Annotationen des Persistenz-Frameworks können wir uns dabei ganz auf die objektorientierte Sichtweise konzentrieren und die Realisierung mittels Fremdschlüsseln vollständig vergessen.
Das folgende Listing zeigt, wie die miteinander verknüpften Datensätze mit Hilfe des EntityManager gespeichert werden können. Hierbei machen wir uns das Attribut cascade aus Listing 47.14 zu nutze, das den Aufruf von persist auch auf die referenzierten Datei-Objekte anwendet.
001 /* Listing4716.java */
002
003 import javax.persistence.*;
004
005 public class Listing4716
006 {
007 public static void main(String[] args)
008 {
009 //Erzeugen einer EntityManagerFactory mit Hilfe des symbolischen
010 //Namens aus dem Persistenz Descriptor (persistence.xml)
011 EntityManagerFactory emf =
012 Persistence.createEntityManagerFactory("persistenceExample");
013
014 //Erzeugen eines EntityManagers für den Zugriff auf
015 //die Datenbank
016 EntityManager manager = emf.createEntityManager();
017
018 //Beginn einer neuen Transanktion
019 EntityTransaction tx = manager.getTransaction();
020 tx.begin();
021
022 //Erzeugen und Verknüpfen der Java-Objekte
023 Verzeichnis dir = new Verzeichnis("temp");
024
025 Datei fileTest = new Datei("test.txt");
026 dir.getFiles().add(fileTest);
027 fileTest.setDirectory(dir);
028
029 Datei fileInfo = new Datei("info.txt");
030 dir.getFiles().add(fileInfo);
031 fileInfo.setDirectory(dir);
032
033 //Speichern des Verzeichnisses und der anhängenden Objekte
034 manager.persist(dir);
035
036 //Abschluss der Transaktion mit einem Commit
037 tx.commit();
038
039 //Freigabe der Ressourcen des EntityManagers
040 manager.close();
041
042 //Schließen der EntityManagerFactory und Freigeben der
043 //belegten Ressourcen
044 emf.close();
045 }
046 }
|
Listing4716.java |
| Titel | Inhalt | Suchen | Index | DOC | Handbuch der Java-Programmierung, 7. Auflage, Addison Wesley, Version 7.0 |
| << | < | > | >> | API | © 1998, 2011 Guido Krüger & Heiko Hansen, http://www.javabuch.de |